RAG is not search with a nicer prompt
RAG reliability comes from retrieval: chunking, embeddings, permission checks, grounded answers with citations, and an evaluation loop.
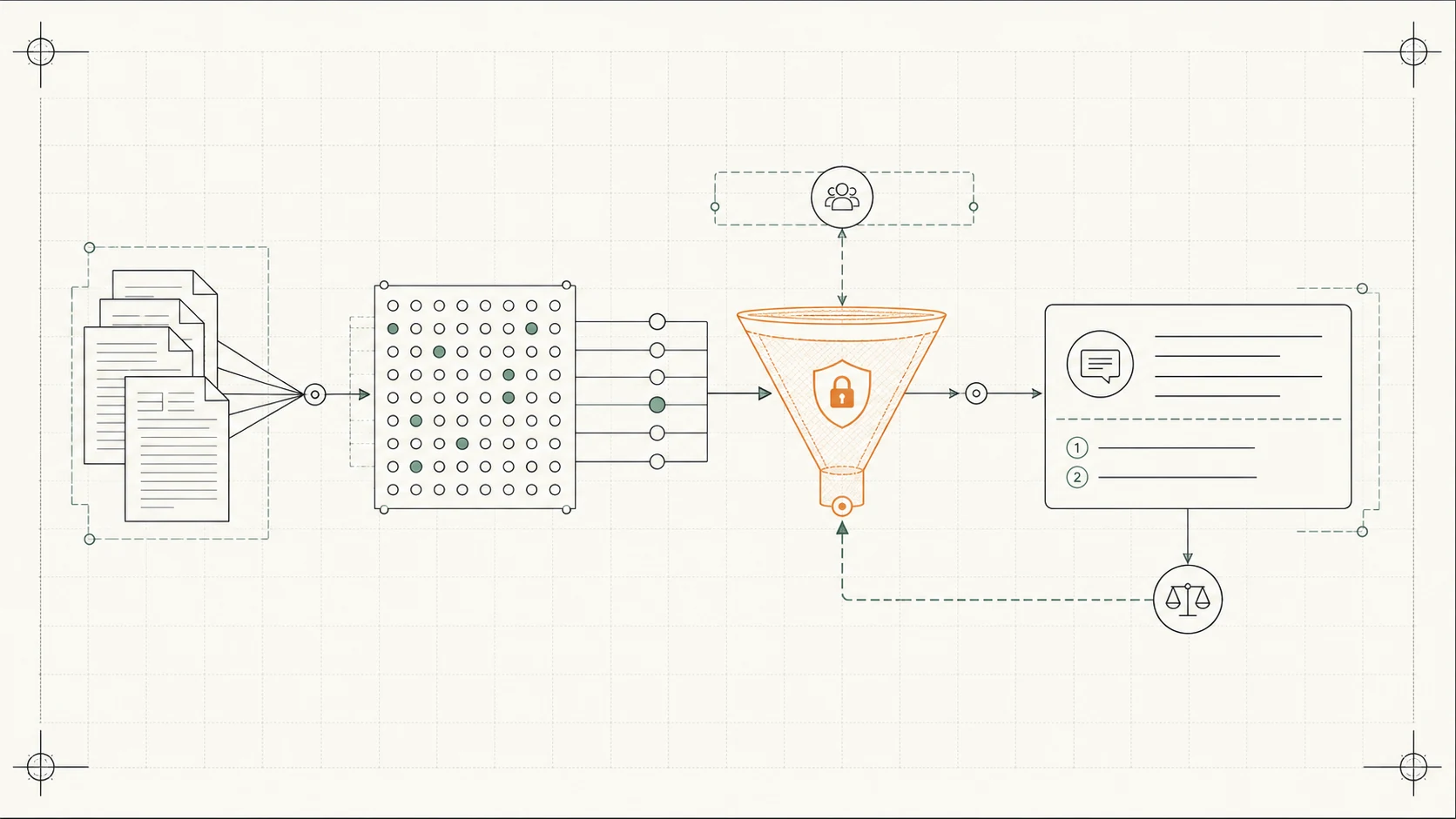
The pitch for retrieval-augmented generation sounds trivial. Take your documents, hand the relevant ones to a language model at answer time, and you get answers grounded in your own knowledge instead of the model’s guesses. The demo works in an afternoon.
Then it meets a real corpus. The answers come back confidently, specifically wrong: citing the wrong policy, missing the obvious document, summarising a file the user was never allowed to open. RAG isn’t search with a nicer prompt. It’s a retrieval system with a language model on the end, and almost all of the reliability lives in the retrieval.
It starts at ingestion
The model only ever sees what retrieval hands it, and retrieval only works on what ingestion built. How you split documents into chunks decides what can be found. Chunk too big, and the one relevant sentence drowns in noise. Too small, and it loses the context that made it mean anything. Embeddings — the numeric fingerprints used to match a question to a chunk — matter just as much. The embedding model and retrieval settings have to suit your corpus, not just a generic benchmark. Get ingestion wrong and no prompt downstream can rescue the answer.
Retrieval is the system
“Retrieve the top results” is the easy part. Retrieving the right results is the whole job. The question a user asks rarely uses the words the answer is written in, so naive matching misses. Good retrieval blends semantic and keyword search, re-ranks the candidates, and is tuned against real questions. The gap between “found something plausible” and “found the thing that actually answers it” is exactly the gap between a confident wrong answer and a correct one.
Permissions belong at retrieval
Here’s the mistake that ends up in an incident report: filtering for permissions after the model has already seen the documents. By then it’s too late. The content is in the context, and the model will cheerfully summarise a file the user can’t open. Permissions have to be enforced at retrieval, so a user’s query can only ever surface what that user is cleared to see. In a company knowledge base this isn’t a nice-to-have; it’s the line between a useful tool and a data leak.
Ground every answer, and cite it
An answer with no source is a guess you can’t check. Make the system answer only from what it retrieved, and attach citations back to the documents it used. Citations do two jobs. They let a person verify the answer in seconds, and they keep the system honest: if it can’t ground a claim in a source, it should say it doesn’t know rather than invent one. “I couldn’t find that” is a feature, not a failure.
It is not always right — so measure it
RAG reduces hallucination; it does not abolish it. Retrieval can miss, a chunk can mislead, the model can over-reach. The teams that run RAG in production treat answer quality as something to measure, not assume. They keep a set of known-good questions and answers, and score the system on every change. A tweak to chunking or retrieval becomes an improvement you can see, not a guess you hope helped. Without that loop you’re flying blind, and “it seems better” is not an evaluation.
The shape of it
RAG is a pipeline: ingest, embed, retrieve under permission, assemble, answer with citations, evaluate. The language model is the last step, not the system. Treat it as a search-and-data problem with a model on the end. Tune the retrieval, enforce the permissions, demand the citations, measure the answers. Then it becomes something you can trust with company knowledge. Treat it as “search with a nicer prompt,” and it will confidently tell you things that aren’t true. This is the unglamorous half of building AI into real systems, and it’s the half that decides whether anyone can rely on it.
Related pattern: RAG knowledge layer — the reusable shape behind this approach.
Keep reading
Building something we should write about?
start a build